고정 헤더 영역
상세 컨텐츠
본문
반응형
|
1. 웹 크롤링이란 웹사이트 html에서 필요한 정보를 데이터베이스로 수집해 오는 작업이다.
2. BeautifulSoup 라는 Library를 이용해 쉽게 크롤링을 할 수 있다.
|
1. 웹 크롤링이랑 웹사이트(html)에서 필요한 정보를 데이터 베이스로 수집해 오는 작업이다.
정의는 개인적으로 한 것이므로 달라질 수 있다. 모든 웹사이트는 html로 구성되어 있다.
각 웹사이트의 html은"F12" 버튼을 통해 확인 할 수 있다.

크롤링을 통해 웹사이트에 원하는 데이터를 가져오기 위해서 html을 이용한다. html은 웹사이트의 모든 data들이 있기 때문에 text로 받아서 내가 원하는 data를 추출할 수 있다.
2. BeautifulSoup 라는 Library를 이용해 쉽게 크롤링을 할 수 있다.
1) requests 와 BeautifulSoup Library를 import한다.
import requests
from bs4 import BeautifulSoup2) requests Library에서 get이라는 function을 통해 html 정보를 class에 받는다.
URL = "https://finance.yahoo.com/quote/O/history?p=O"
req = requests.get(URL)
print(type(req))==> 결과는
<class 'requests.models.Response'>
이다. 따라서 req는 단순이 class 일뿐이다.
해당 class에 들어가서 살펴보면
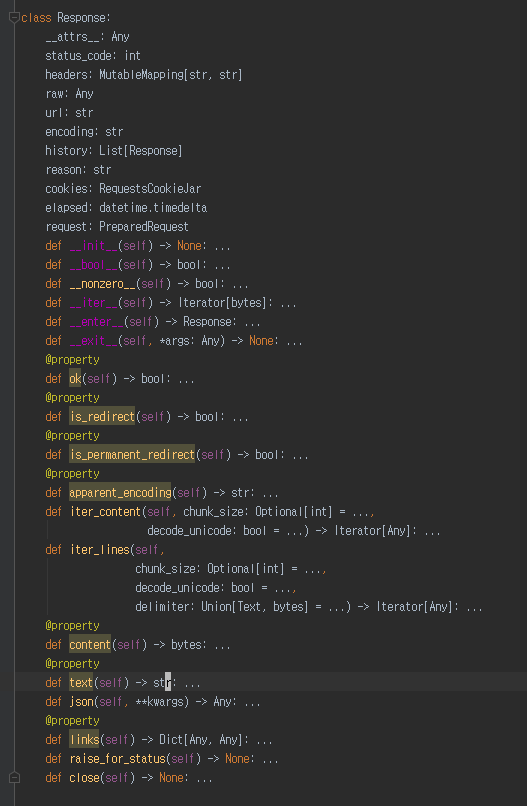
사진 설명을 입력하세요.
다음과 같은 코드를 확인 할 수 있고 text라는 function을 쓰면 str로 변환해 주는 것을 추측할 수 있다.
3) 위에 class에서 html 정보를 text로 변환시켜 준다.
html = req.text
print(type(html))
==> 결과는
<class 'str'>
이다. 나는 string인 줄 알았는데 지금 보니 앞에 class가 붙어있다. 해당 Library에서 정의한 건가 하는 생각도 있다.
4) BeautifulSoup를 통해 html data를 해석한다.
soup = BeautifulSoup(html, "lsml")
print(type(soup))html은 html data이다. "lsml"은 data를 어떤 형식으로 해석할지이다.
==> 결과는
<class 'bs4.BeautifulSoup'>
이다.
5) prettify를 통해 유니코드을 return 해 줄 수 있다.
유니코드가 무엇인지 정확한 의미가 와닿지 않지만 출력했을 때 들여쓰기가 되어 있다. html 코드를 보기 좋게 만들 어주는 기능을 하고 있다고 알아두면 될 것 같다.
print(soup.prettify())==> 결과는
<html>
...
...
...
</html>
같이 출력 된다.
반응형
'프로그래밍' 카테고리의 다른 글
| Verilog 인터넷에서 무료 사용하는 법(EDA Playground) (0) | 2021.10.28 |
|---|---|
| LFSR 원리와 C 코드 만들어보기 (1) (0) | 2021.10.20 |
| <Python> : : Anaconda 이용해서 Python Library 설치 방법(Python 장점) (0) | 2020.03.26 |
| <블로그> : : 구글 검색 상위 페이지 아무나 하나 , google search console 등록해야 하지 !! (티스토리 google search console 등록하는 법) (0) | 2020.03.11 |
| <IT> : : 갤럭시 윈도우와 연결해서 사용하는 법 (스마트폰으로 찍은 사진 컴퓨터에서 가장 쉽게 보는 법) (0) | 2020.03.04 |





댓글 영역